O(n) complexity for long sequences
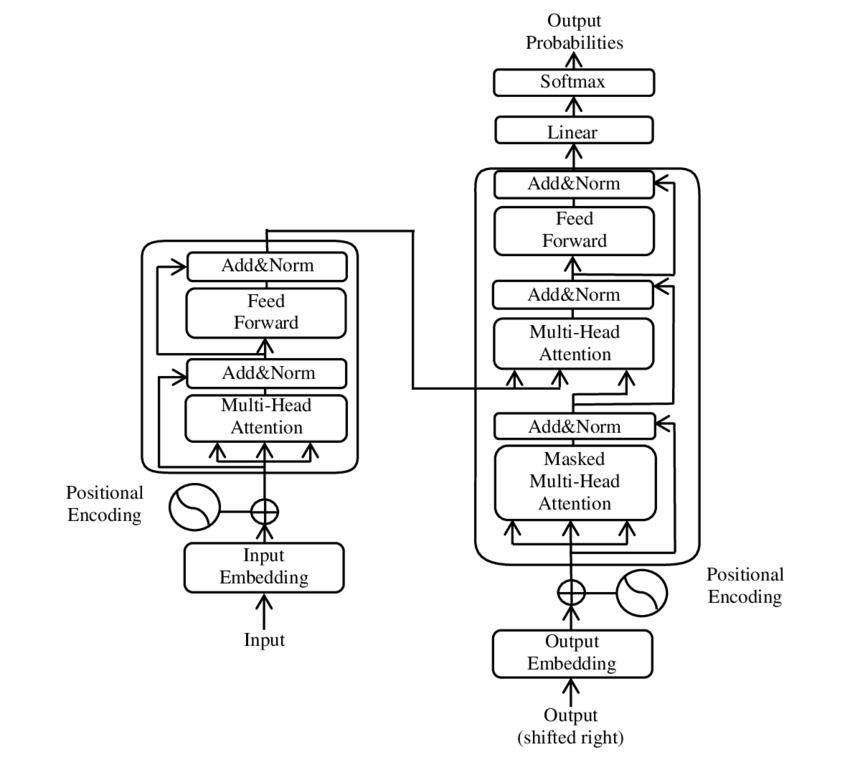
Attention Is All You Need
O(n) complexity for long sequences
The sliding window attention mechanism allows the transformer to handle long sequences without the prohibitive computational costs, enabling applications like machine translation, question answering, and multimodal generative AI to operate more efficiently.
Example
In machine translation, the sliding window attention mechanism enables the transformer to quickly and accurately translate long sentences by focusing on relevant segments of the input sequence, rather than processing every possible pair of words.
Understanding the sliding window attention mechanism's O(n) complexity is crucial for developing efficient AI systems that can process long sequences without incurring excessive computational costs.
Related concepts
Attention (machine learning)
Flash attention speeds up processing by tiling attention across input, avoiding N×N matrix materialization
ring attention does: distributes long sequences across multiple devices
Ring attention distributes long sequences across multiple devices
paged attention (vLLM) improves serving throughput
Paged attention (vLLM) improves serving throughput by reducing latency through non-contiguous KV-cache pages, enabling faster data retrieval
the vocabulary size matters: larger vocab = shorter sequences but more parameters
Larger vocab reduces sequence length, increasing model complexity and parameters
Masking (behavior)
Causal masking prevents attention to future tokens in the decoder
Binary search
Time complexity of binary search: O(log n) — halves search space each step
One email a day: 5 concepts + the 5 stories that matter →
Swipe through 100 ML concepts daily
Open TickerNews