ONNX format standardizes model representation for cross-framework deployment
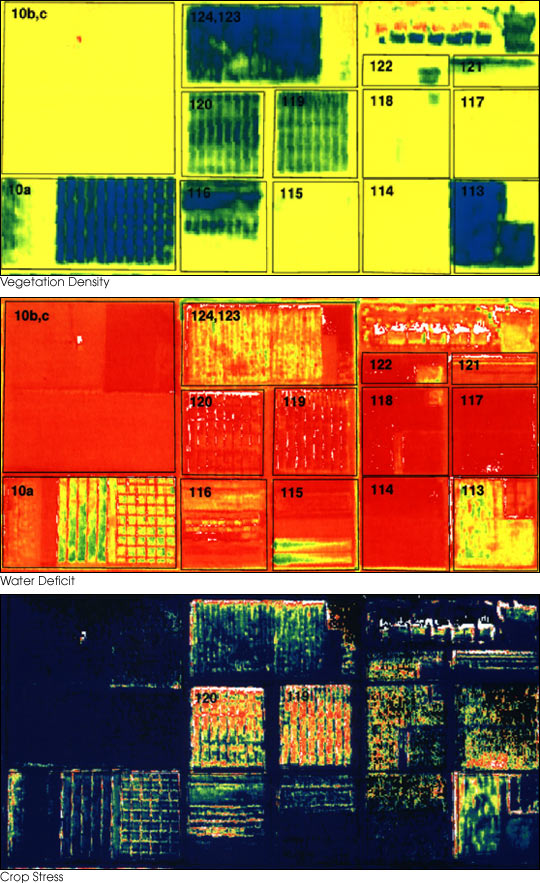
Image: Susan Moran, Landsat 7 Science Team and USDA Agricultural Research Service (U.S. Government work), Public domain, via Wikimedia Commons
the ONNX format does: standardizes model representation for cross-framework deployment
ONNX format standardizes model representation for cross-framework deployment
Related concepts
MoE models have more parameters but similar compute cost
MoE models distribute parameters across k experts, reducing active experts' compute cost
to standardize: when you need zero mean and unit variance for gradient-based optimization
Standardize when zero mean and unit variance are required for gradient-based optimization
weight tying does in language models: shares embedding and output projection matrices
Tying reduces the number of parameters by sharing embedding and output projection matrices
XLA does for TensorFlow/JAX: compiles computation graphs for TPU/GPU execution
XLA compiles computation graphs for TPU/GPU execution
load balancing loss is needed in MoE
Load balancing loss in MoE prevents expert collapse by distributing workload evenly across experts
Large language model
LLMs can generate, summarize, translate, and analyze text in many contexts
One email a day: 5 concepts + the 5 stories that matter →
Swipe through 100 ML concepts daily
Open TickerNews