Most transformer operations are memory-bound due to large model sizes requiring extensive data transfer
Image: Yuening Jia, CC BY-SA 3.0, via Wikimedia Commons
most transformer operations are memory-bound, not compute-bound
Most transformer operations are memory-bound due to large model sizes requiring extensive data transfer
Related concepts
Tesla Model Y
Tesla Model Y is the world's best-selling electric vehicle in 2023
kernel fusion reduces memory bandwidth bottleneck
Kernel fusion reduces memory bandwidth bottleneck by combining multiple operations into a single kernel, minimizing data transfers
Pre-LN transformers are easier to train
Pre-LN transformers use residual connections, allowing gradients to flow more smoothly during backpropagation
transformers use LayerNorm not BatchNorm
LayerNorm normalizes across all features, accommodating variable-length sequences unlike BatchNorm, which relies on fixed-size batches
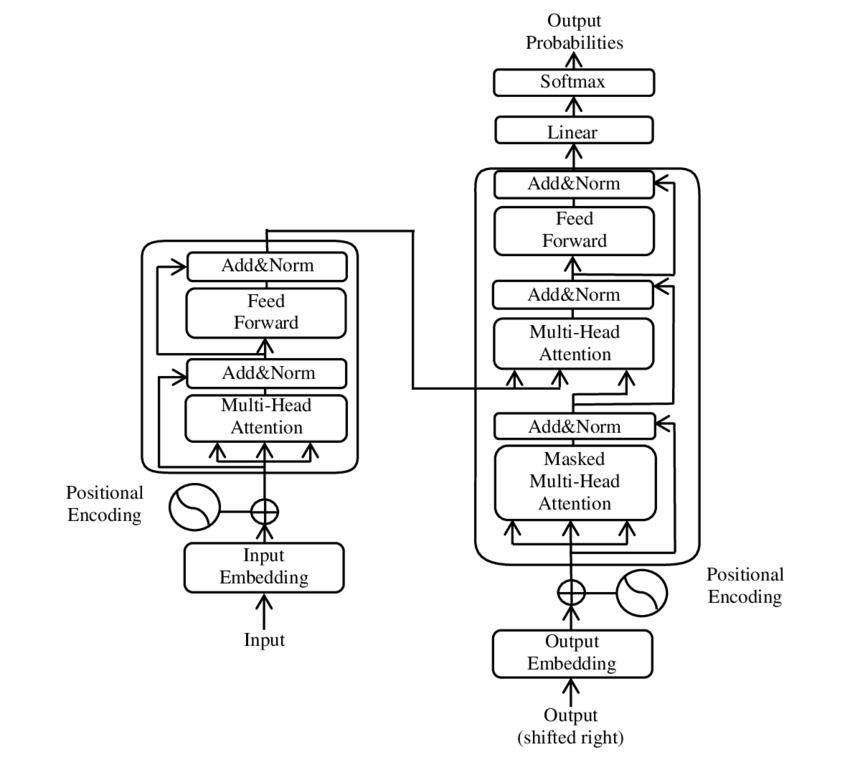
Transformer (deep learning)
Transformers use multi-head attention for contextualizing tokens
fused kernels do
Fused kernels combine multiple operations into one kernel to avoid memory round-trips
One email a day: 5 concepts + the 5 stories that matter →
Swipe through 100 ML concepts daily
Open TickerNews