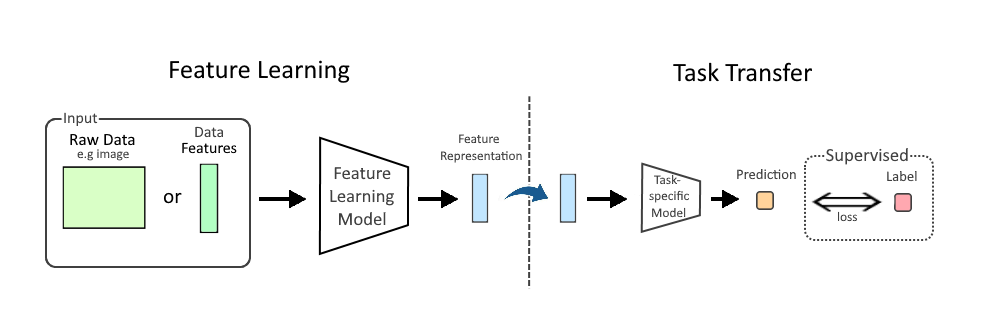
LayerNorm normalizes across all features, accommodating variable-length sequences unlike BatchNorm, which relies on fixed-size batches
Image: Fgpacini, CC BY-SA 4.0, via Wikimedia Commons
transformers use LayerNorm not BatchNorm
LayerNorm normalizes across all features, accommodating variable-length sequences unlike BatchNorm, which relies on fixed-size batches
Related concepts
Batch norm vs layer norm: BN across batch, LN across features
Batch norm (BN) normalizes across batch, layer norm (LN) normalizes across features; LN handles variable-length sequences
to use an RNN/LSTM: for sequential data where order matters (mostly replaced by transformers)
Use RNN/LSTM for sequential data where order matters (mostly replaced by transformers)
Pre-LN transformers are easier to train
Pre-LN transformers use residual connections, allowing gradients to flow more smoothly during backpropagation
most transformer operations are memory-bound, not compute-bound
Most transformer operations are memory-bound due to large model sizes requiring extensive data transfer
sinusoidal position encoding works: each dimension has a different frequency
Sinusoidal position encoding assigns unique frequencies to each dimension, enabling the model to distinguish positions effectively
Transformer (deep learning)
Transformers use multi-head attention for contextualizing tokens
One email a day: 5 concepts + the 5 stories that matter →
Swipe through 100 ML concepts daily
Open TickerNews