OLS minimizes squared differences
Ordinary least squares
OLS minimizes squared differences
The Gauss–Markov theorem states that OLS estimators are the best linear unbiased estimators (BLUE) when certain assumptions hold true. This theorem guarantees the efficiency of OLS estimators in linear regression models.
Example
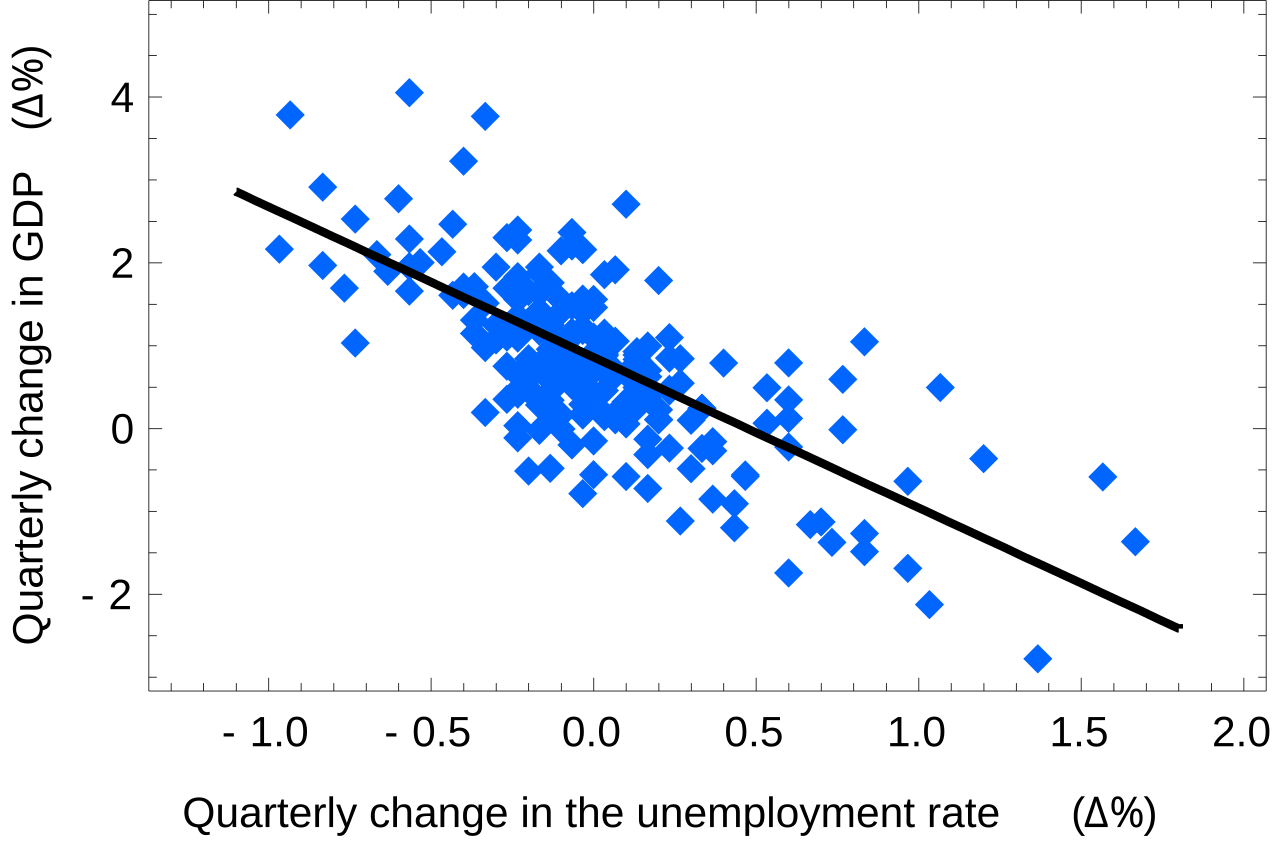
Consider a dataset with observed values (y) and predicted values (ŷ) from a linear regression model. The OLS method calculates the best-fitting line by minimizing the squared differences (y - ŷ)².
Understanding OLS is crucial for accurate parameter estimation and model fitting in linear regression analysis.
Related concepts
Regularization (mathematics)
L1 regularization results in sparse solutions
non-convex loss landscapes are hard: many local minima and saddle points
Non-convex loss landscapes are hard due to many local minima and saddle points
Proximal gradient methods for learning
Proximal gradient descent efficiently handles non-differentiable L1 regularization by combining gradient descent with a proximity operator
random projection to O(log n/ε²) dimensions preserves pairwise distances within 1±ε
Random projection reduces dimensionality while preserving pairwise distances within ε² due to the Johnson-Lindenstrauss lemma
The elastic net combines L1 and L2: λ₁|w| + λ₂w² gives both sparsity and stability
Elastic net: λ₁|w| + λ₂w² enforces sparsity and stability simultaneously
the Johnson-Lindenstrauss lemma says
Random projection reduces dimensionality while approximately preserving pairwise distances
One email a day: 5 concepts + the 5 stories that matter →
Swipe through 100 ML concepts daily
Open TickerNews